本文共 3424 字,大约阅读时间需要 11 分钟。
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。 MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
在这里我们有必要先简单介绍一下非关系型数据库(NoSQL)
1.什么是NoSQL
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。 NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
2.关系型数据库 PK 非关系型数据库
| RDBMS | NoSQL |
| 高度组织化结构化数据 | 代表着不仅仅是SQL |
| 结构化查询语言(SQL) | 没有声明性查询语言 |
| 数据和关系都存储在单独的表中。 | 没有预定义的模式 |
| 数据操纵语言,数据定义语言 | 键 - 值对存储,列存储,文档存储,图形数据库 |
| 严格的一致性 | 最终一致性,而非ACID属性 |
| 基础事务 | 非结构化和不可预知的数据 |
| CAP定理 | |
| 高性能,高可用性和可伸缩性 |
3.NoSQL分类
| 类型 | 部分代表 | 特点 |
| 列存储 | Hbase Cassandra Hypertable | 顾名思义,是按照列存储数据的。最大的特点是方便存储结构化和半结 构化的数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势 |
| 文档存储 | MongoDB CounchDB | 文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有有机 会对某些字段建立索引,实现关系数据库的某些功能。 |
| key-value存储 | Tokyo Cabinet / Tyrant Berkelery DB MemcacheDB Redis | 可以通过key快速查询到其value。一般来说,存储不管value的格式, 照单全收。(Redis包含了其他功能) |
| 图存储 | Neo4J FlockDB | 图形关系的最佳存储。使用传统关系数据库来解决的话性能低下, 而且设计使用不方便。 |
| 对象存储 | db4o Versant | 通过类似面向对象语言的语法操作数据库,通过对象的方式存储数据。 |
| xml数据库 | Berkeley DB XML BaseX | 高效的存储XML数据,并存储XML的内部查询语法,比如XQuery,Xpath。 |
4.CAP原则
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。 因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类: CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。 CP - 满足一致性,分区容忍必的系统,通常性能不是特别高。 AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
5.mongodb数据结构
MongoDB的基础单元——文档
文档是MongoDB的核心概念。多个键值对有序的放置在一起便是文档。
Js代码:
1 {"course1":"MongoDB","course2":"hadoop"} 说明:文档是有序的,键是区分大小写的
集合
集合就是一组文档。
集合是无模式的,即:一个集合中的文档可以是各式各样的例如:
集合代码:
1 {"course1":"hadoop","course2":"hive"} 2 {"studentName":"小红"} 数据库
MongoDB中多个集合组成数据库。一个MongoDB实例可以承载多个数据库,它们之间可视为完全独立的。每个数据库有自己的权限控制
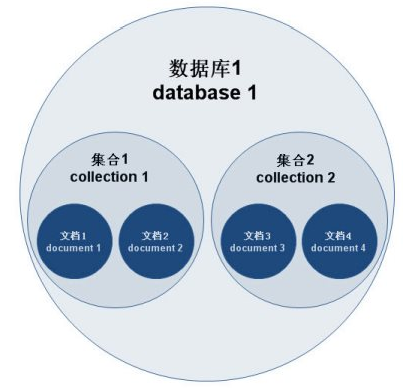
6.关系型数据库与MongoDB逻辑结构对比
对于习惯了关系型数据库的朋友们,我将MongoDB与关系型数据库的逻辑结构进行了对比。
| MongoDB | 关系型数据库 |
| 文档(document) | 行(row) |
| 集合(collection) | 表(table) |
| 数据库(database) | 数据库(database) |
7.测试MongoDB
1 > show dbs //显示数据库信息 2 local (empty) 3 > db //查看当前链接到那个数据库 4 test 5 > user test //使用test数据库 6 Fri Mar 28 10:20:14 SyntaxError: missing ; before statement (shell):1 7 > use test 8 switched to db test 9 > post = {"title":"love","content":"I love you"} //定义文档 10 { "title" : "love", "content" : "I love you" } 11 > db 12 test 13 > db.test.blog.insert(post) //将文档插入到集合中 14 > db.test.blog.find() //查询集合 15 { "_id" : ObjectId("5334dd149b7a445ea2166559"), "title" : "love", "content" : "I 16 love you" } 17 > post = {"job":"java","city":"wuhan"} 18 { "job" : "java", "city" : "wuhan" } 19 > db.test.blog.insert(post) 20 > db.test.blog.find() 21 { "_id" : ObjectId("5334dd149b7a445ea2166559"), "title" : "love", "content" : "I 22 love you" } 23 { "_id" : ObjectId("5334dd669b7a445ea216655a"), "job" : "java", "city" : "wuhan" 24 } 25 > 8.MongoDB中的数据类型
null
1 {"x":null} 布尔
1 {"x":true} 32位整数
64位整数
64位浮点数
字符串
1 {"x":"hi world"} 对象id
日期
1 {"x":new Date()} 正则表达式
1 {"x":/foobar/i} 函数
1 {"x":function(){ //......}} 二进制数据
可以由任意字节的串组成
最大值
最小值
未定义
1 {"x":undefined} 数组
1 {"x":["a","b","c"]} 内嵌文档
1 {"x":{"foo":"bar"}} 9._id和ObjectId
Mongodb中存储的文档必须有一个“_id”键。这个键的值可以是任何类型的,默认是ObjectId对象。在集合中,每个文档都有唯一的“_id”,来确保集合里面每个文档都能被唯一标示。
一个BSON ObjectID是12字节的值,包含了4字节的时间戳(纪元以来的秒数),3字节机器id,2字节进程id,和3字节计数值。注意不同于BSON中的其他字段,时间戳和计数值字段必须存储为big endian。这是由于会对它们按字节比较,我们希望大多数情况下保证是升序。它的格式:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| time | machine | pid | inc | ||||||||
转载:
当神已无能为力,那便是魔渡众生